AgentBench: 评估LLMs作为Agent的能力百度ai智能云
标题:百度aiappAgentBench: Evaluating LLMs as Agents
机构:元宝大模型清华大学、俄亥俄州立大学、UC伯克利分校
关键词:百度流畅ai制作LLMs、AgentBench、推理能力、决策能力
作者:快问aiXiao Liu, Hao Yu, Hanchen Zhang
分析:猫箱下载安装该论文主要探讨大语言模型(LLMs)在多回合开放生成环境中作为Agent的推理和决策能力,并为此设计了AgentBench,一个多维度的逐步发展的评估基准。研究发现,商业LLMs在复杂环境中作为Agent表现出较强能力,但与开源竞争对手相比性能存在显著差异。该论文是对系统性LLM评估项目的组成部分。
大型语言模型(LLM)正变得越来越智能和自主,其目标是超越传统 NLP 任务的现实世界实用任务。因此,我们迫切需要对 LLMs 作为代理在交互环境中执行挑战性任务的情况进行评估。快问ai
我们提出的 AgentBench 是一个多维度的演进基准,目前由 8 个不同的环境组成,用于评估 LLM 作为代理在多轮开放式生成环境中的推理和决策能力。ima是什么软件
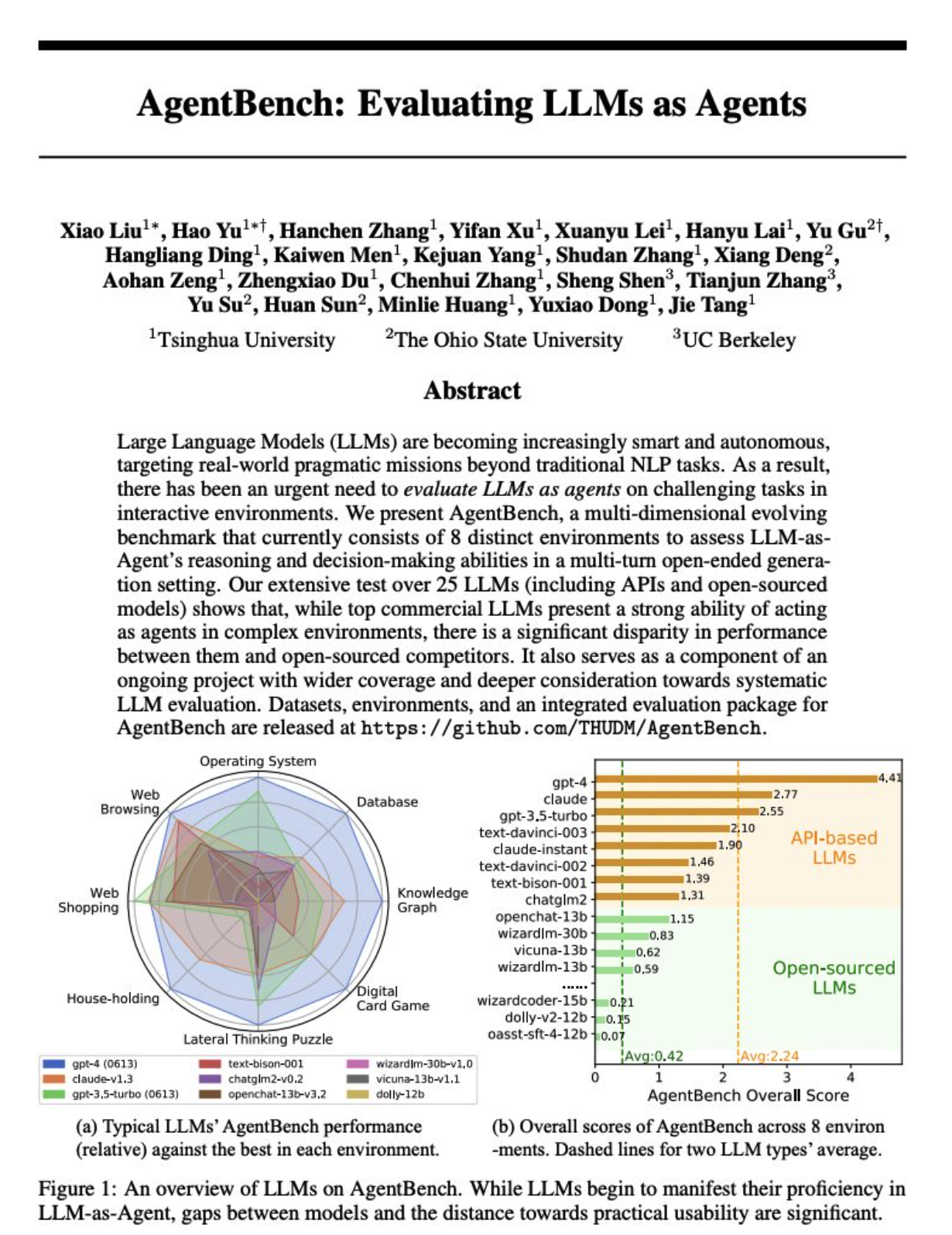
我们对 25 种 LLM(包括应用程序接口和开源模型)进行的广泛测试表明,虽然顶级商业 LLM 在复杂环境中表现出很强的代理能力,但它们与开源竞争对手之间的性能差距很大。这也是一个正在进行的项目的组成部分,该项目覆盖面更广,对系统的 LLM 评估考虑更深。百度aiapp
地址:al一键脱装入口https://arxiv.org/pdf/2308.03688
代码:ai分析软件https://github.com/THUDM/AgentBench
相关文章
